There is an icon for every sport, Tiger Woods for Golf, Michael Phelps for Swimming, Roger Federer for Tennis, Kobe Bryant for Basketball etc. this information is current, because better athletes are being produced over time for these types of sports. Boxing however has taken a slightly different path, since the early 2000's there hasn't been a rise of any boxing greats, unlike other sports. When one thinks of the sport Boxing, sure there have been plenty of boxing legends since the sport first developed, however two boxing kings come to mind, either Muhammad Ali, or Mike Tyson. These two boxers, although retired, are known as two of the greatest of all time. Now when boxing is the subject for conversation, it always seems to find its way asking the same question that's been asked for the past decade: 'Who would Win? So for this project I chose to design a datavisualisation that compares career statistics between Muhammad Ali and Mike Tyson. It consists of three pages:
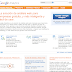
First page - This page is the introductory page, it has Ali on the left and Tyson on the right, each has a record line that goes down the page, their first fight (top of the page) to their last fight(it cuts off on the first page design but would scroll down the page if it were an actual web page). It is a list of mostly Wins and Losses, there is also a legend in the middle of the page that describes certain fight results eg. Title Wins and Losses etc. Eg. by clicking on one of the results, say a W (Win), information on that fight appears under the boxer's face, in this case I have chosen to use Ali's first Title Win and Tyson's first Title Win, so information on both of those fights appear under their faces. On this page there is also the 'COMPARE' button, after choosing two results from both the lists, hitting the compare button takes you to the second page.
Second page- Hitting the COMPARE button navigates you to the second page. I have designed this page to make it look like a pre-fight pay per view style poster, that takes the results of all the fights leading up to this big fight just like in real life. Again it has ALI on the left and TYSON on the right of the page. At the top it has another legend, this is to compare the boxers, depending on which result you click on (in this case it's the two first Title Wins for both boxers) it will have further information on the two pages. On this page it shows how many times the boxer has been knocked down and knocked out, this gives the viewer a rough idea on how well each boxer can take a punch (this is only for comparison and does not effect datavisualisation which I will explain on page 3) It displays each boxers current record as well as KO's leading up to the datavisualisation fight. It also displays which 'type' of Muhammad Ali and Mike Tyson are fighting, in this design its 22 year old Ali vs 20 year old Tyson, as well as whether or not they are champions at the time. Down the bottom of this page displays two 'PRIME' graphs for each fighter. It highlights the period in their careers of when each boxer was in his prime. Based on Ali's fighting record, he was in his prime five years longer than Tyson, of course Tyson went to jail and made some poor career decisions along the way which could arguably be a contributing factor. The 'PRIME' graphs are constructed based on consecutive wins and losses between the two boxers, Tyson has more consecutive losses and No Contests than Ali towards the end of his career, these are against fighters that he would 'statistically' easily annihilate in his prime . Then there is the 'RESULT' button, which navigates you to the datavisualisation.
Third page - The datavisualisation, the big fight. At the top of this page there is a legend, this is how the datavisualisation is generated. I have used the most important aspects of Heavyweight boxing to compare and ultimately design this datavisualisation. Wins, Knockouts, Years within prime and Title Belts. I've chosen not to include the 'times knocked down and times knocked out' stats in the datavisualisation because I want the design to support the idea that a knockout or a knockdown is caused by three things: Emotion, the other boxer and fighters prime. 1.Emotion does not factor in boxing statistics, so at the end of the day, statistics are mainly there for comparison, it's different as soon as the boxers step in the ring, take the Mike Tyson vs Buster Douglas upset for example, which is considered one of the biggest upsets in boxing history. 2. The boxer who scores the knockdown or knockout gets these achievments put on their stats. It's the other boxers skill (or luck) that essentially determines a knockout, and 3. whether a boxer is in their prime. A boxer out of his prime is more likely to get knocked out, so 'years out of prime' is what effects the datavisualisation. This datavisualisation is to determine, based on 'statistics' and age, who is more likely to win. In the middle of the page is the datavisualisation of the fight. I have appropriately used boxing gloves for the visualisation, Ali in blue and Tyson in red. What the viewer takes away from this visualisation is an instant perception on which colour glove is more dominant. Based on the information in this particular design, I have chosen 22 year old WBA/WBC (two world heavyweight title belts) heavyweight champion Muhammad Ali to fight against 20 year old WBC heavyweight champion Mike Tyson. Based on the datavisualisation, 'statistically' the fight would be extremely even. They both get 10 gloves for each title belt, a glove for each knockout, and a glove for each year within their prime (this is for maturity). So at the bottom of this page I have added that if a colour glove is more dominant by 10 gloves or more, than the result of this particular fight would 'statistically' be more likely to conclude by way of knockout. Within 10 gloves, it would more likely result in a decision, this is a fun way for the viewer to get a sense of realism out of the visualisation for this particular fight result. If for example I was to choose Muhammad Ali's first Title Win and get 22 year old Muhammad Ali, and choose Mike Tyson's last fight (which was a loss), the datavisualisation would be very different. Tyson has 50 wins at this stage of his career, including his 44 knockouts, so based on these statistics Tyson would be more likely to win. However we must also consider that at this stage of his career he is 39 years of age, so based on the 'PRIME' graph, he is 9 years out of his prime, which subtracts 90 of Tyson's red gloves (-10 gloves for each year) from the visualisation, resulting in Ali's blue gloves being much more dominant. So based on the way the datavisualisation is generated, If a 22 year old Muhammad Ali and 39 year old Mike Tyson were to fight, 'statistically' Muhammad Ali would be most likely to win by way of knockout.
Because these are two of the biggest names in boxing history it wasn't too hard for me to obtain their career stats. These two links -
http://boxing.about.com/od/records/a/tyson.htm and
http://boxing.about.com/od/records/a/ali.htm have a great time-line for both careers. Including date of each fight, fight results, fight opponents and fight locations.